Пункт шестой — «Построение прогноза продаж: автоматическая обработка прогноза»
В данной статье я расскажу, что включает в себя автоматическая обработка прогнозного значения, полученного нами по какому-либо методу из прошлой статьи.
Под обработкой прогноза я подразумеваю набор некоторых процедур, которые делают прогноз более корректным, очищая от каких-либо мелких ошибок или наоборот, дополняя его полезной информацией. То, о чем я здесь напишу, не является обязательным, но учет всех этих пунктов/процедур поможет повысить вашу точность прогнозирования, а также поможет избежать некоторых ошибок, которые могут возникнуть, при взятии прогноза в работу коллегами и смежными отделами.
В содержании ниже перечислен список процедур, которые будут разобраны в статье:
Содержание
И да, постараюсь написать обо всем попроще, не так как в прошлой статье.
Доверительный интервал
Первое, что входит в обработку прогноза — это определение доверительного интервала. Сразу скажу, я им не пользуюсь и он для меня не очень интересен. Но так как в интернете по запросу «прогнозирование продаж», достаточно часто встречается упоминание доверительного интервала, я тоже решил его здесь добавить.
Доверительный интервал — это такие границы прогноза, в которые скорее всего попадет будущее фактическое значение с определенной заданной вероятностью, которую мы сами и задаем. Эти границы определяются следующей формулой:

где Y — наше прогнозное значение, σ — среднеквадратическое отклонение истории продаж, n — количество периодов в истории продаж, а t — коэффициент доверия.
Коэффициент доверия зависит от заданной нами вероятности попадания в границы прогноза. Чем больше желаемая вероятность попадания будущего фактического значения в доверительный интервал, тем выше должен быть коэффициент доверия и тем «шире» будут границы интервала. Ниже представлены частные случаи коэффициентов доверия:
- Фактическое значение попадет в доверительный интервал с вероятностью 90% — коэффициент доверия должен быть равен 1,64
- Фактическое значение попадет в доверительный интервал с вероятностью 95% — коэффициент доверия должен быть равен 1,96
- Фактическое значение попадет в доверительный интервал с вероятностью 99% — коэффициент доверия должен быть равен 2,6
Для других «нестандартных» вероятностей, коэффициент доверия определяется по таблице функций Лапласа, которую можно легко найти в интернете. Плюс ко всему, в Excel можно легко определить доверительный интервал, с помощью функции ДОВЕРИТ или ДОВЕРИТ.НОРМ, в аргументах которых как раз указывается необходимая вероятность попадания.
Для чего это нужно? Для того, чтобы обнаружить какие-либо серьезные отклонения от прогноза. Если мы рассчитали, что фактическое значение с вероятностью 99% должно попасть в доверительный интервал прогноза, а оно не попало, то данный прогноз стоит проанализировать и выявить причину отклонения, чтобы в будущем ее можно было бы учесть.
Стоит отметить, что для определения доверительного интервала необходимо использовать сглаженный числовой ряд, то есть очищенный от трейд-маркетинговых активностей. В противном случае, доверительный интервал может быть настолько большим, что какое-то явное отклонение от объемов продаж будет считаться адекватным.
Учет сезонности
Здесь я совсем немного расскажу о наложении сезонности на прогнозное значение. Напомню, что в одной из прошлых статей, я писал о расчете коэффициентов сезонности. После получения прогнозного значения, необходимо эту сезонность «наложить» (при условии, что используемый метод прогнозирования ее не учитывал). Здесь все проще простого — прогнозное значение умножаем на коэффициент сезонности соответствующего периода. Если прогноз равен 200 килограмм, а сезонность 105%, то показатель прогноза с наложенной сезонность 200*1,05 = 210 килограмм.
Обнуление объемов SKU, выведенных из ассортимента
Самая простейшая обработка прогноза. Я уже упоминал, что желательно проделывать данный пункт при подготовке корректной истории продаж до консолидации данных. Однако, если консолидации никакой нет, ассортимент небольшой и сама история продаж «простая» — очистку от лишних прогнозов или обнуление можно провести после построения всех прогнозов.
В моих инструментах очистка от лишних SKU «ДО» происходит для клиентов, которые консолидируются по группам, а обнуление «ПОСЛЕ» идет по позициям, которые мы вообще вывели из ассортимента всех клиентов. Если вы считаете, что никакой очистки и обнуления быть не должно — смело игнорируйте этот пункт.
Обнуление прогнозов для клиентов в ПДЗ
По сути, принцип данной обработки такой же, как и в предыдущем пункте. Здесь мы обнуляем объемы определенного клиента, который находится в статусе ПДЗ (просроченная дебиторская задолженность) и в следствие этого заблокирован. Если у Вас есть такие данные, и вы уверены, что клиент не выйдет из ПДЗ в тот период, на который вы строите прогноз, то рекомендуется прогнозы для такого клиента обнулить. В противном случае, можно также игнорировать данный пункт.
Распределение промо-объемов
Здесь все быстро и просто. В статье «Распределение промо» мы разобрали механику распределения промо-объемов. Если у нас никакой трейд-маркетинговой активности нет в принципе, то игнорируем этот пункт. А если есть — накладываем промо согласно выявленной механики на полученные прогнозные объемы. Ничего лишнего.
Округление объемов
Часто-используемая обработка прогноза в моих инструментах — это округление объемов. Не буду утверждать, что оно крайне необходимо при прогнозировании, но иногда данная обработка бывает крайне полезна.
Случаев, при которых используется округление объемов, несколько:
- Если мы прогнозируем объемы поштучно — зачастую может получиться дробное число. Производить нецелое количество продукции мы не можем, поэтому такое количество необходимо округлить до большего целого.
- Если мы прогнозируем объемы в штуках, но отгружается продукция в коробах, упаковках или в какой-либо другой таре — необходимо округлять полученное количество до штук, кратных этой таре. Например, мы спрогнозировали 8 штук чего-либо (пусть будет, упаковок молока), а по факту, мы их отгружаем по 5 штук в коробке. Естественно, мы не будем отгружать одну целую коробку, а 3 упаковки молока без коробки. Поэтому полученный прогноз, опять же, необходимо округлить до объемов, кратных коробке. Для этого необходимо использовать дополнительный справочник, в котором будет содержаться вся необходимая информация о количестве штук какой-либо номенклатуры в одной таре.
- Если мы прогнозируем в килограммах (или в другой мере массы). Здесь точно так же, как и в предыдущих пунктах: необходимо округлять либо до полноценной массы одной штуки, либо до массы тары, в которой поставляется определенное количество штук той или иной номенклатуры.
Что касается моих инструментов и предприятия, на котором я работаю в данный момент: почти вся продукция отгружается в коробах, а активное количество номенклатур постоянно меняется, какие-то выводятся из ассортимента, какие-то вводятся. Поэтому, не всегда хочется каждый раз актуализировать справочник «штук в коробке». Чтобы свести к минимуму влияние ошибки округления, я стал использовать НОД (наибольший общий делитель).
С помощью инструмента, автоматически находится НОД всех продаж, а затем, полученное прогнозное значение округляется до ближайшего числа, которое будет кратно полученному НОДу (если значения дробные, то для корректного расчета я умножаю их на 1000, а потом полученный по ним НОД делю на 1000). Как раз такая обработка изображена на примере ниже:
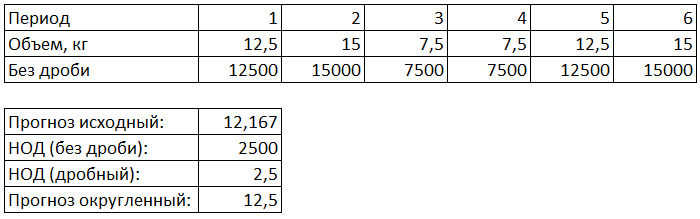
Хочу отметить, что если у Вас в базе данных хранится информация о количестве штук в таре/коробе/упаковке той или иной номенклатуры, то лучшим способом округления будет создание SQL-подключения к БД для полуавтоматического формирования справочника, по которому будет округляться прогноз. Если же такой информации нет — используйте НОД-округление, либо создавайте и обновляйте такой справочник вручную.
Обработка прогноза: итоги
Хочу отметить, что все виды обработки прогнозных значений не являются обязательными, ими можно пренебречь, они всего лишь делают прогноз либо более информативным (как в случае с доверительным интервалом), либо более корректным/правильным (как в случае с округлением).
Также, здесь я не учел листинги, потому что работа с ними почти такая же, как и с промо-активностью: знаете, что листинги будут — накладываете. А так в целом всё. Если у Вас есть еще какие-то идеи или предложения по обработке полученных прогнозов — можете написать о них здесь, в комментариях.
Спасибо. Гениально простой подход к округлению через НОД! Гениально просто! Спасибо.