Любому человеку, который занимается прогнозированием продаж, важно и необходимо оценивать корректность своих прогнозов. Для этого существует такой показатель, как «Точность прогнозирования». В данной статье именно о нем я и расскажу.
Хочу обратить внимание на то, что в некоторых компаниях данный показатель называют «Аккуратность прогнозирования». Не могу сказать, что это неправильно, но в данной статье будет фигурировать именно «Точность прогнозирования». Ведь мы оцениваем насколько точно наш прогноз совпадает с фактическими значениями, а не аккуратность, с которой мы его высчитывали.
Точность прогнозирования — это показатель, который характеризует качество прогноза. Он отражает насколько сформированный прогноз совпадает с истинными фактическими значениями.
«Точность прогнозирования»: формула, разновидности «ошибок прогноза».
Итак, чтобы рассчитать точность прогнозирования, необходимо сначала рассчитать ошибку прогнозирования в процентах, а затем, вычесть ее из 100%:
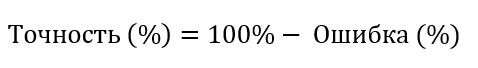
В качестве основной ошибки для расчета точности прогнозирования мы будем использовать Взвешенную Абсолютную Процентную Ошибку (WAPE — Weighted Absolute Percent Error), которая рассчитывается по формуле:
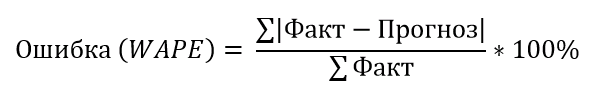
То есть: сумма всех отклонений прогноза от факта по модулю, деленное на сумму всех фактов и умноженное на 100%.
Важно! Если ошибка прогнозирования больше 100%, то точность прогнозирования всегда будет равна 0%.
Вообще, помимо WAPE (которую также называют MAD-Mean Ratio), существует множество ошибок, которые мы можем использовать в качестве основной ошибки для расчета точности прогнозирования. Например:
- Средняя Абсолютная Процентная Ошибка (MAPE — Mean Absolute Percent Error)
- Средняя Процентная Ошибка (MPE — Mean Percent Error)
- Медиана Абсолютной Процентной Ошибки (MdAPE — Median Absolute Percent Error)
- Средняя Абсолютная Масштабированная Ошибка (MASE — Mean Absolute Scaled Error)
И так далее (более подробно смотрите здесь). Однако при расчете точности прогнозирования, WAPE — наиболее оптимальный вариант ошибки, так как он наименее чувствителен к выбросам и искажениям, а также интуитивно-понятен и прост в расчете. В общем, WAPE — наш выбор!
Итоговая формула примет вид:
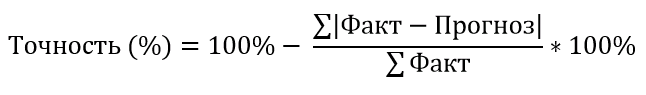 Про другие ошибки здесь я писать не буду, потому что и использовать мы их не будем, но если у Вас есть желание ознакомиться с ними, рекомендую к прочтению статьи «A survey of forecast error measures» и «Another look at measures of forecast accuracy», а также книгу «Forecasting: Principles and Practice». К сожалению, русскоязычной информации на просторах всемирной сети на эту тематику не очень много, поэтому для изучения материала необходимы минимальные знания английского языка.
Про другие ошибки здесь я писать не буду, потому что и использовать мы их не будем, но если у Вас есть желание ознакомиться с ними, рекомендую к прочтению статьи «A survey of forecast error measures» и «Another look at measures of forecast accuracy», а также книгу «Forecasting: Principles and Practice». К сожалению, русскоязычной информации на просторах всемирной сети на эту тематику не очень много, поэтому для изучения материала необходимы минимальные знания английского языка.
Примеры расчета точности прогнозирования:
Итак, формула расчета точности у нас есть, теперь мы перейдем непосредственно к примеру расчета:
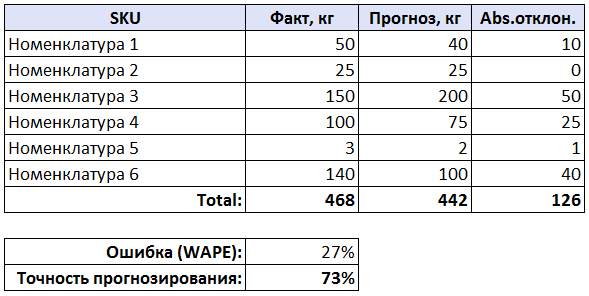
Все просто. У нас есть исходные данные: SKU, факт продаж и прогноз продаж. Для каждого SKU мы находим отклонения по модулю (|факт-прогноз|), а затем суммируем их, получаем 126. Затем суммируем все фактические показатели, получаем 468. Находим ошибку прогнозирования: делим сумму отклонений на сумму фактических показателей — 126/468 = 0,269, то есть 27%. И вычитаем значение ошибки прогнозирования из 100% и получаем точность 73%. Средний результат.
Также, бывают ситуации, когда необходимо рассчитать не общую точность по всем номенклатурам, а отдельно по каждому клиенту (или номенклатурной группе, или по каналам продаж и т.д.). На таблице ниже изображен изображен именно такой пример:
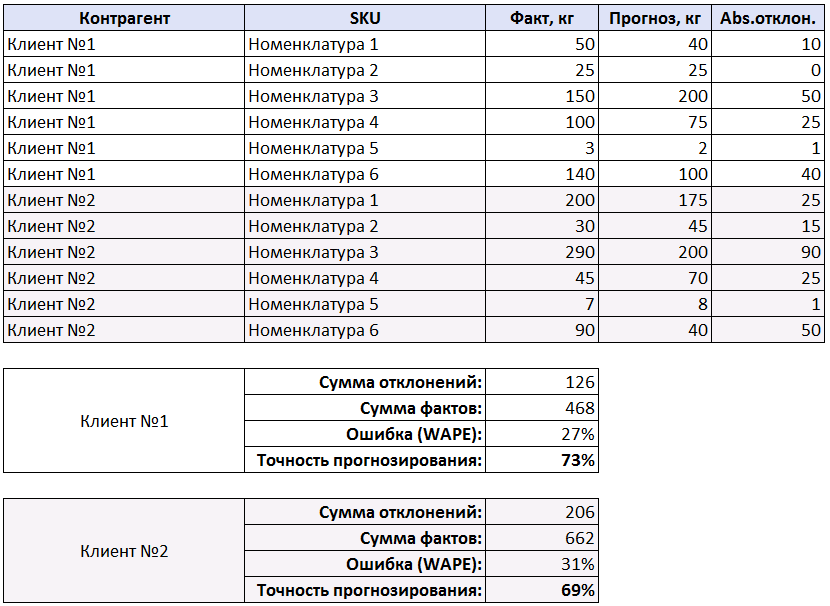
Суть расчетов не меняется, только теперь находим сумму отклонений и сумму фактов для каждого из клиентов по отдельности. Для первого клиента ошибка прогнозирования равна 126/468 = 27%, соответственно точность равна 73% (то же самое, что и в первом примере), а для второго клиента ошибка прогнозирования равна 206/662 = 31%, и точность равна 69%.
В общем-то и все. Мы нашли точность прогнозирования отдельно для списка SKU и отдельно по каждому клиенту. Важно(!) помнить некоторые правила:
- Если ошибка прогнозирования (WAPE) больше 100% — точность прогнозирования всегда 0%. Математически можно записать это так: Точность = Maximum of (1 — Ошибка, 0)
- Если сумма фактов равна нулю (ошибка подразумевает деление на сумму фактов, а на ноль делить нельзя), то рассматриваем два случая:
- если прогноз тоже = 0, то точность всегда равна 100%
- если прогноз ≠ 0, то точность всегда равна 0%
- Перед нахождением точности необходимо проконсолидировать данные, то есть просуммировать объемы по одинаковым позициям (для более подробной детализации — просуммировать объемы по одинаковым позициям для каждого элемента детализации).
Файл с примерами из статьи можно скачать здесь.
Это просто космос. Спасибо автору!
И Вам спасибо!
Здравствуйте, спасибо за подробное разъяснение) А отдельно по всем «ошибкам прогноза» статьи не будет?
Добрый день.
Будет! Думаю, в ближайшее время напишу.
Добрый день, благодарю за статью, очень пригодилась)
Здравствуйте!
Это просто какое то чудо, спасибо за материал!
Здравствуйте! Рад был помочь!
Здравствуйте! Спасибо большое за статью.
Поясните пожалуйста логику, почему если прогноз больше факта в 3 раза, то точность 0%, если наоборот (меньше в 3 раза) — то 33%.
Евгений, здравствуйте!
Об этом как раз написано в конце статьи в первом правиле: «Если ошибка прогнозирования (WAPE) больше 100% — точность прогнозирования всегда 0%».
Считается, что точность прогнозирования всегда находится в диапазоне от 0% до 100%, поэтому любая отрицательная точность (как раз она получается в Вашем примере) всегда округляется до нуля.
Думаю, грубовато, но справедливо можно провести аналогию с дартсом: либо вы попали в мишень и смотрите куда именно, либо не попали вообще и вам все равно, в какую часть стены воткнулся дротик (это в любом случае учитываться не будет).
Возможно неправильно выразился.
Я понимаю, что отрицательное значение округляется до 0. Я немного про другое. Пример рассчитанный по этой методике:
Прогноз 5, факт 15 — точность прогноза = 0.33
Прогноз 15, факт 5 — точность прогноза = 0 (округлённое до 0 отрицательное значение)
Почему так? В моём понимании завысить прогноз в 3 раза это такая же ошибка как и занизить прогноз в 3 раза.
Все, понял.
Ошибка, по которой высчитывается прогноз в статье — называется WAPE, то есть «взвешенная абсолютная процентная ошибка».
Суть в том, что у этой абсолютной ошибки есть «вес», и зависит он именно от значения факта. Чем меньше факт, тем больше на точность прогнозирования влияет одна и та же ошибка. В этом как раз и суть метода WAPE.
В Вашем примере, в обоих случаях, отклонение от факта по модулю (то есть абсолютная ошибка), будет равно 10. Но в первом случае (10 от 15), WAPE не такая значимая как во втором (10 от 5), так как фактическое значение в первом случае больше, и поэтому воздействие на точность прогнозирование в обоих случаях разное.
Спасибо!
Здравствуйте! Спасибо за статью!
Но есть вот такой вопрос — а как правильно консолидировать данные на более высокие уровни?
С элементарным уровнем данных (SKU- Клиент) всё понятно.
А далее…
По продукции: SKU -> Подгруппа продукции -> Группа продукции
По клиентам: Клиент -> Ответственный менеджер (несколько клиентов) -> Регион
Конечно понятно, что самый верхний уровень (вся продукция – вся компания) вряд ли имеет практический смысл.
Варианта два:
1) Вычисляем абсолютную ошибку на элементарном уровне. Суммируем факты и ошибки. Вычисляем точность.
2) Суммируем факты и прогнозы, и уже по этим результатам рассчитываем ошибку. Вычисляем точность.
Результат будет не одинаков. И это зависит от того какие ошибки (+ или-) преобладают на элементарном уровне.
Возможно, что я, как дилетант в этой области, вообще что-то путаю, уж извините пожалуйста.
Очень интересно ваше мнение.
Большое спасибо!
Виктор, здравствуйте!
«самый верхний уровень (вся продукция – вся компания) » — вообще, такая детализация имеет место быть. Часто она используется в небольших компаниях с небольшой структурой. Либо в компаниях, где за прогнозирование отвечает один человек/отдел, без участия других (особенно если нет никаких промо-активностей). Также, такая детализация позволяет поверхностно ответить на вопрос «повлияло ли прогнозирование на недопоставки или списания без определения какого-то либо виновника».
Далее, я так понимаю, вы имеете ввиду более расширенную детализацию точности прогнозирования, вероятно, для расчета KPI тех же менеджеров.
Наиболее корректен первый вариант, но предварительно его необходимо «раздробить» на нужную вам детализацию (как у меня во втором варианте примера, только вместо контрагентов можно использовать менеджера, или и менеджера, и контрагента и вообще расширить как Вам нужно) и уже потом по каждой из номенклатур для всех уровней детализации считать отклонения (ошибки). А потом уже да, суммировать факты и отклонения (например по какому-то определенному уровню детализации, например менеджеру) и высчитывать точность.
При использовании второго варианта, точность прогнозирования будет некорректной.
Самый простой пример:
Менеджер спрогнозировал 100 единиц продукции №1, №2 и №3, по факту клиент заказал 100 единиц продукции №4, №5, №6. Суммарно, 300 единиц прогноза и 300 единиц факта, точность 100%, но по факту все спрогнозировано абсолютно неправильно.
Артём, здравствуйте!
Спасибо за ответ!
Про KPI точно не скажу, я сторонний программист, пару лет назад сделал для одной компании такой “Forecasting
Tool” на базе MS Access + Excel.
Но проблема точности прогноза у них точно есть.
Компания – производитель шоколада. Производство в Европе, то есть недопрогноз быстро не ликвидируешь. Перепрогноз тоже чреват — товар с ограниченным сроком годности, приходится распродавать в убыток.
Дистрибуция – через российские компании-дистрибьюторы и сети (это то, что я назвал Клиент). Их несколько десятков, во всех регионах России.
Первоначальные прогнозы делают ответственные за конкретного клиента менеджеры. Всё собирается, конечно центральный офис имеет возможность корректировать.
Вот такая картина 🙂
Думаю что начнём с менеджеров.
Скажите пожалуйста, а вот в последнем (третьем) примере (его нет на этой странице, он только в файле Excel) всё правильно?
Мне кажется, что это как раз метод 2. Или тут какая-то идея скрыта?
Да, в третьем примере в файле Excel все правильно.
Суть вот в чем: во втором примере мы раздробили данные на контрагента и SKU, чтобы посчитать точность по контрагентам (это то, что находится под таблицей, как раз то, о чем писал в предыдущем комментарии)
А в третьем примере, мы все обратно сконсолидировали только к SKU (к такому же виду, как и в первом примере), то есть схлопнули все вместе до уровня номенклатур, просуммировав данные по одинаковым номенклатурам (только факт и прогноз).
И точно также дальше высчитываем точность прогнознирования: находим абсолютное отклонение по каждой SKU, суммируем их, также суммируем факты, находим ошибку WAPE, а затем и саму точность. То есть все возвращается в первому Вашему предложенному варианту.
Насчет производства шоколада, мне казалось, что у шоколада достаточно большой срок годности: то есть очень плохой прогноз можно было бы компенсировать увеличенными складскими остатками. Но тут, опять же, зависит от площади складов, производственных мощностей, прибыли и самого типа продукции (возможно, у каких-нибудь конфет срок годности действительно невысокий). В любом случае, для корректного страхового запаса, нужно разработать приемлемую модель с учетом кучи факторов и условий (тот же учет ABC/XYZ-анализа, допустимого уровня сервиса, ОСГ и т.д.), а для корректного планирования, либо совершенствовать инструмент (опять же, улучшая модель или приобретая серьезные инструменты прогнозирования), либо менять общий подход к прогнозированию (например, передать процесс прогнозирования на отдельного человека/отдел, который будет компетентен в вопросах прогнозирования, а также будет видеть всю картину по объемам целиком). А в идеале, должен быть комплексный подход: и к закупкам, и к складским запасам, и к прогнозированию.
Артём, спасибо!
Конечно будем совершенствовать, мы пока ещё в начале.
Обязательно поизучаю и другие Ваши статьи.
Артем, спасибо большое за емкую, понятную статью!
Я бы добавила такой показатель, как BIAS. Все-таки он тоже важный и порой нужный. Точность, по факту, показывает попал-не попал, на сколько попал. А BIAS еще и показывает, что именно-то произошло…. Не долетел, или все-таки перелетел с продажами.
Еще раз спасибо Вам за ваш сайт. Ничего лучше, я пока так и не нашла на просторах интернета. Респект.
Эльвира, спасибо за добрые слова!
Про BIAS думал еще во время написания статьи, но в какой-то момент решил, что он будет лишним.
Не отрицаю важности данного показателя, как раз можно понять образовываются ли у нас неликвиды на складах, или наоборот, повышается ли количество недопоставок (и, как следствие, снижается уровень сервиса). И тут мы уже конкретно сможем понимать, на какой процесс нам нужно оказывать влияние, но это уже идет более серьезный анализ точности прогнозирования с погружением в какую-то конкретную детализацию.
Но все равно, огромное Вам спасибо, что обратили на это внимание! Возможно, спустя некоторое время, я буду обновлять статью и как раз про BIAS пару строк напишу.